



Products
Solutions
Resources
Company

Application protection, broadly defined as making it very difficult to reverse-engineer application code and preventing tampering with the intended behavior, makes use of various techniques, but one of the most effective and easy to understand is obfuscation.
It's pretty obvious why obfuscation is so prevalent in application protection: Developers write code to be understood, maintained, and extended by other developers. As a result, they make sure to have a clear and obvious structure, with code organized into modules, and with easily identified data-flow. If the code is imagined to be a book, it is written to be an enjoyable read, easily digestible in a single sitting, with informative chapter headings and a complete cross-index of all keywords!
However, the same attributes of such code that make it easy to understand to developers also make it easy to understand to malicious actors. Had the developers violated every principle of good software development, and written a bunch of "Spaghetti Code", reverse engineering and tampering with the code would be vastly more difficult.
Software obfuscation gives applications the best of both worlds: Write the code in the clear, structured manner that is best for development, and then turn it into the equivalent of a pile of unstructured spaghetti-code that will be extremely painful to reverse engineer.
Software obfuscation might seem to be “old hat” these days. Application developers are familiar with the importance of name obfuscation, and code obfuscation approaches like control flow flattening (CFF) have been standard practice for years. At the same time we are continually seeing advances in reverse engineering, especially with the release of ever easier to use frameworks that incorporate increasingly sophisticated analysis and tampering techniques. These frameworks allow nearly anyone to defeat many existing code hardening and RASP protections, including a lot of traditional obfuscation techniques. You may be forgiven for thinking that in the Cat vs. Mouse game of mobile application protection, the reverse engineering cat is winning, so in this blog I'd like to draw attention to a number of advanced software obfuscation approaches that should keep the mouse alive for many years to come.
Although the application source code is compiled to a sequence of low-level instructions (e.g. Java becomes bytecodes), the high-level language constructs (like an "if/then/else" or a loop) will be expressed as an easily identifiable group of basic blocks (sequences of low-level instructions with a single entry-point, terminated by a branch). Furthermore, source code constructs, such as classes and methods, typically result in clearly identifiable patterns of prologue and epilogue instructions. This allows the reverse engineer to decompose the application binary into its original structural elements. Finally, low-level call instructions clearly identify locations where methods are invoked, and the parameters that are passed to them. Code obfuscation techniques, such as CFF, are all about erasing these structural traces of the original source code.
Function merging is a code obfuscation technique in which a number of unrelated function bodies are “merged” into a single mega-function, and the original calls to the individual functions are replaced by a call to the merged function, along with the introduction of some data-flow to identify the correct control flow in the merged function body. This new data-flow can be as simple as an additional integer parameter: The merged function then utilizes that data to determine which original body to dispatch to.
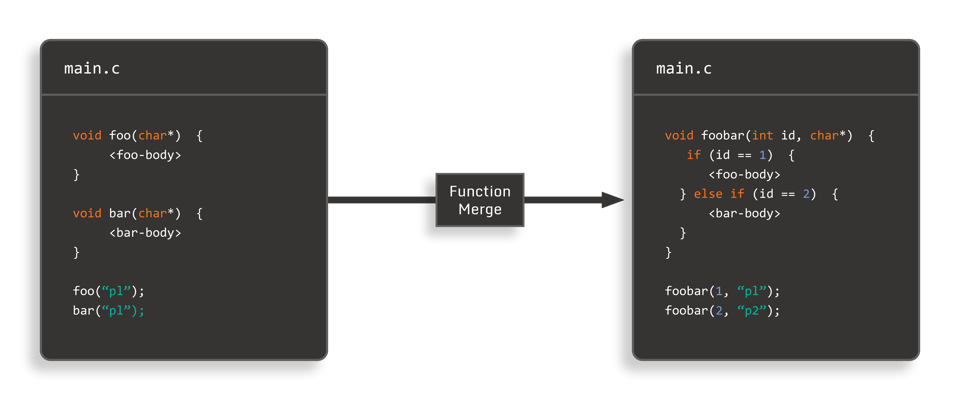
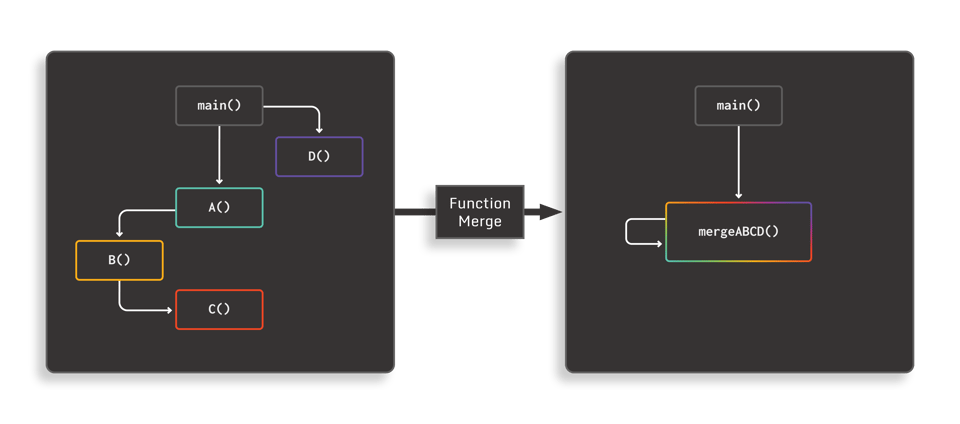
In addition to making call-graph analysis more difficult (since we’ve effectively collapsed the original graph to a much smaller one), function merging creates function bodies with a much larger number of basic blocks. This increases the opportunities for classic control-flow obfuscation techniques, such as CFF, while at the same time expanding the scope of these normally intra-procedural techniques to inter-procedural.
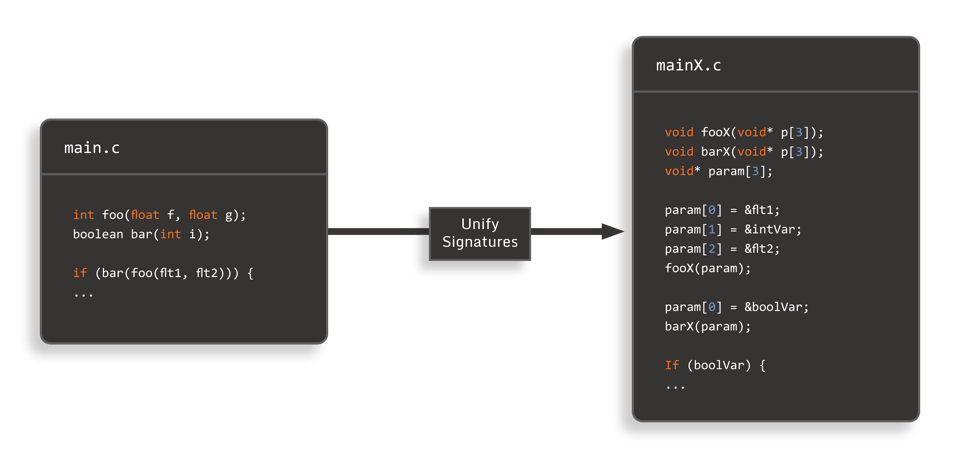
Another important code structural element we would like to obscure are the signatures of methods (how many and what type of parameters they take, as well as what they return). With method signature unification, we use the approach of passing a single pointer parameter, which is the address of an array of pointers in which the original parameters (and even the return value, if any) are mapped to individual elements of the array. Before each method call, the original parameters must be marshaled into the parameter array, and after return, the return value must be retrieved from the array.
To obscure the somewhat obvious marshaling code, we can introduce spurious "dummy" parameters, split parameters into multiple entries (e.g. make it so that two array entries must be added together to recover the original value), or entangle parameters together. With this approach, all methods end up with the same signature (a single pointer as argument), thus making it more difficult to determine what their purpose is. Additionally, function merging becomes even easier to perform, and the result of this is a very small number of methods, which seem to call each other over and over again.
Calling a method involves passing parameters and returning a result, and this is accomplished at the application binary level by using a calling convention. A calling convention specifies how these parameters and return values are passed between methods (e.g. using registers, on a stack, and how that stack is managed by the caller and callee). Reverse engineering tools recognize the low-level code to marshall parameters and return values (e.g. instructions like push or pop) and use that information to determine the signatures of methods and understand data-flow in the application. Making use of a non-standard calling convention is thus a powerful code obfuscation technique.
In the following figure, the left side shows the x86_64 instructions for calling a function which sums four integers using a standard calling convention (passing the parameters in registers, and returning the result in theeaxregister), and the right side shows functionally equivalent code that does things in a non-standard manner (parameters are passed using a mix of registers and the stack, and the result is returned in theediregister):

Many other approaches can be taken to pass parameters and return values, such as utilizing our own stack (potentially growing in the “wrong” direction), or “hoisting” local variables to global storage locations.
If we are using method signature unification, this additionally gives us an opportunity to modify the calling convention rather simply, since the pre-allocated array of pointers it utilizes for parameter/return-value passing can serve as a virtual stack in itself.
Another interesting code obfuscation technique is virtualization, in which the original low-level instructions are transformed into bytecodes for a custom virtual machine (VM) implementation. At runtime, the custom VM interprets these bytecodes and executes the original low-level instructions they were derived from. With this approach, we can completely replace the standard binary representation of the application code, preventing static analysis tools from even recognizing the code. The primary disadvantage of this approach is the potentially large performance overhead it can introduce, since each custom bytecode instruction may require thousands of VM instruction cycles to interpret. Without proper implementation, it cannot be used wholesale.
Since virtualization is potentially quite expensive, it is typically only applied to small sections of the code, which limits its effectiveness. Rather than virtualizing the entire instruction set, we can consider virtualizing just the branch-target addresses themselves. Normally, reversing frameworks scan for these branch instructions and record their targets, which is then used to compute the call-graph, and also to identify basic software constructs such as loops, if-statements, etc. Branch target virtualization replaces instructions performing a branch, call, or return operation with a call to a branch-target “Oracle” function. This keeps track of the current state of the application code – what code we are executing, and where control-flow should go next – based on its knowledge of the original application logic, call-graph, and the state of conditional flags. This has the effect of removing static branch addresses in the code (since branch targets are now computed), and completely flattening the call-graph.
Beyond the structure and logic of the code itself, another important element of the original source code that survives to the application binary are data values, such as integer constants, strings, etc., and the way they flow through the code. Data value obfuscation simply changes the representation of these data values so they are no longer statically present in the application binary. In the case of an "interesting" integer value (e.g. AES S-box constants such as0x637C777B, 0xF26B6FC5, etc. can help to identify the location of an AES crypto operation), we can decompose it into a number of arbitrary constants that must be summed together to compute the original constant (and of course, much less obvious computations can be used to achieve the same result). We can go further and encrypt the original constant, and then perform a corresponding decryption at runtime before using it, which is particularly appropriate for string constants.
With data transforms, we take the idea of data value obfuscation a step further, and transform not just the data constants themselves, but also the mathematical operations on those values (e.g. arithmetic or logical operators). Data transforms are applied to storage locations, which is where high-level entities, such as class members, variables, and parameters, reside in application memory. This approach modifies the standard binary representation of numbers – typically a sequence of bits encoding the magnitude of the value, and an optional sign bit – and effectively defines a new mathematical representation for the contents of a storage location and all the operations that access it.
A simple example would be to apply the linear transform to the storage location where the integer variablefooresides. For example,foo’=A*foo+B, withA being a scaling constant andBan offset constant. Iffoowas initially set to 0, we would now set it to the constantB. To incrementfoo’by 1, we would addA. All the standard operations, such as add, multiply, etc., are well-defined mathematically in the transformed representation. Moreover, we can also define operations for storage locations with distinct transforms. For example, ifbaris transformed tobar’=C*bar+D, then the statementfoo’+=bar’can be computed with exposing the untransformed values of eitherfooorbar.
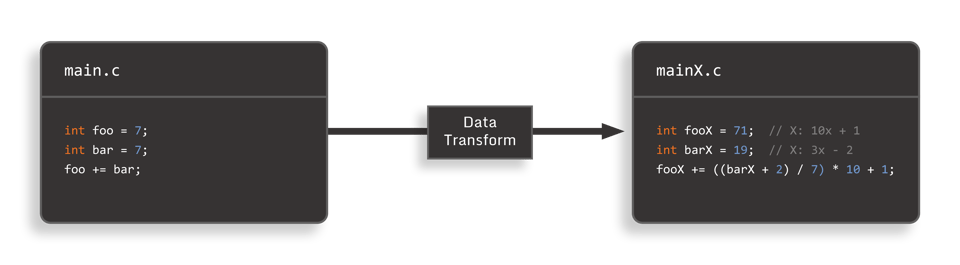
Care must be taken when selecting the specific data transformation “family.” Simple transforms, such as XOR’ing, with a constant leave obvious clues in the code, while more sophisticated transforms can inflate arithmetic operations that were previously a single instruction by factors of 10’s or even 100’s.
But this overhead can be worth it; data transforms result in code, similar to whitebox cryptography, in that data values and the code that makes use of them are both transformed and entangled. If the reverser wishes to modify the contents of a storage location (say to increment the variable containing the current score in a game), they have to first reverse the data transform. Additionally, the fact that we can have arbitrarily many distinct transforms – both individual transform families along with the values for the intrinsic constants – means that data transforms have huge potential to challenge reversers.
Compilers generally have fixed policies for how compound types (structs, arrays, etc.) are laid out in memory, usually just in sequential locations, possibly with some padding between elements of different sizes. Reverse engineering tooling relies on recognizing these simple schemes in order to “decompile” the low-level memory into high-level objects. We can also transform these layouts by putting the elements of an array into non-contiguous memory locations, or by chopping a 32-bit integer field in a struct into two smaller, non-contiguous 16-bit locations, for example. This, in turn, allows us to mix layout transforms with data transforms, meaning that both the location and the mathematical representation of individual values are modified.
With this approach, we can arrange it so that the value of a given struct field must be computed by summing two sub-fields and other even more complex schemes. The primary difficulty of this technique is that all access (getter and setter) code for the layout transformed objects must be correctly identified and transformed. This is a challenging problem, particularly in the presence of storage location access via pointers and pointer aliases.
All of the data obfuscation techniques discussed above are primarily about eliminating the static traces of the original data values, as well as making it harder to tamper with them dynamically. However, they don’t address the issue of obfuscating where those data values flow, and ideally preventing identification of which code consumes them. Data flow obfuscation attempts to break the obvious traces of data flow, typically by using non-standard ways to communicate the data that traditional data-flow analysis can’t detect.
For example, we could use a pipe or even a file to communicate values from one piece of code to another, and especially if the name of the I/O entity is encrypted, static analysis would no longer see the data-flow. Another approach, which works well for arrays, objects and other data accessed by pointers, is to intentionally introduce aliased pointers – multiple pointers, computed at runtime, but all of which point to the same memory location – since pointer alias analysis is a challenging problem to solve.
The harsh reality is that readily available and easy-to-use reverse engineering tools and frameworks make it extremely straightforward to identify application code and data of interest to a malicious actor, and permit tampering with an application’s intended behavior. To combat this, obfuscation is one of most tried and tested mobile application protection techniques. While some of the classic techniques, such as name obfuscation and control flow flattening, are frequently applied, given the sophistication of modern reversing frameworks, it is important to consider a multi-layered approach using various obfuscation techniques that effectively entangle with each other.
In this blog, I’ve described several advanced obfuscation techniques, and while some of them can be both challenging to implement and incur substantial overhead (i.e. data transforms), others, such as branch target virtualization and method signature unification, are much more practical.
There’s still a lot of life left in the old dog of obfuscation.
