



Products
Solutions
Resources
Company

As more and more businesses develop and release apps, and as more of their business logic begins to reside on the app side, implementing proper code hardening techniques is becoming critically important. Code hardening is the best way to prevent tampering with an app’s source code for the purposes of stealing IP, committing monetary fraud, getting an app or in-app purchase for free, and many other goals that drive hacker behavior.
Code obfuscation is the standard technique to prevent hackers from decompiling or reverse engineering source code. Although code hardening is very effective when properly implemented, recent app security research conducted by Guardsquare found that the majority of Android financial services apps do not use any code hardening techniques at all. Moreover, of those who do use some code hardening, a huge majority limit their obfuscation techniques to name obfuscation alone.
They primarily use open source optimizers, like our own open source product ProGuard or R8, which have positive impacts on app performance by shrinking them, but provide only limited security. It’s key that businesses understand the need to take the next step.
Taking a deeper look at implementations in the wild, less than 10% of the top 3,000 financial services Android apps use additional code protection techniques beyond name obfuscation. These are apps that contain extremely sensitive information that, if accessed by the wrong people, can lead to fraud and reputational damage, among other negative consequences.
The aim of this blog post is to explain why name obfuscation alone is insufficient to protect mobile apps against the most prevalent attacks.
Developers tend to choose meaningful names for classes, functions, and variables. This improves the readability of their software and makes it easier to debug. For instance, let’s take a look at the (simplistic) code below in Example 1.
You don’t need to have much—if any—programming experience to understand what this code snippet is about; all of the involved class, function, and variable names speak for themselves.
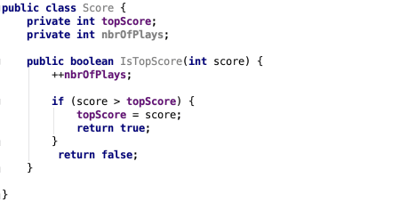
Example 1 - Unobfuscated code snippet, which shows that it can be trivial to understand what the various components are used for within the mobile app
To apply name obfuscation security techniques, you would simply replace these names with meaningless alternatives, as in Example 2 below. At first glance, this code may seem less readable for humans because the class, function, and variable names are not self-explanatory anymore. But … is it actually very difficult to put back together?

Example 2 - A name obfuscated code snippet. While the names are less meaningful, the entire program logic remains untouched and can be easy for hackers to reassemble
We can compare this to a book where the index was removed and the names of all characters and locations were modified. Does this really make the book less readable? Sure, the main character is now called “A$be23E3!a” and lives in “qV2D%87VqpwR,” but a reader can still understand the story because the sequence of events remains untouched. It might take a little longer to read, at least until your brain gets used to the nonsense strings, but you’ll still be able to understand the plot and finish reading the book, likely without any critical meaning lost.
This metaphor holds for name obfuscated code. Since the entire program logic remains untouched, it’s not very difficult for a hacker who has decompiled this code to understand what the intended aim of a specific class or function is. The hacker can rebuild the “index” of the “book” on their own, and understand how the code works, without much trouble.
Even worse, for (de)compilers, it doesn’t matter at all if a name is “John” or “A$be23E3!a,” because (de)compilers are not making any assumptions based on names anyway. So any reverse engineering tool will figure out your source code with no trouble, even after name obfuscation has been applied to it.
Returning to Example 2, even during the first read, it remains clear—especially to anyone with even basic programming experience—that variable “b” remains the one to beat, and that this check is done in function “d,” which is publicly accessible in class “a.”
For these reasons, name obfuscation is not sufficient protection for a mobile app’s source code. In fact, it is only effective if combined with additional obfuscation techniques.
To effectively secure an app’s code, you’ll need to combine name obfuscation with additional Android app obfuscation techniques. Here are a few of the major types and how they work:
Control flow obfuscation will alter the structure of a mobile app’s code. It’s an essential step to increase the complexity of the program logic, so that even decompilers will not be able to parse it.
Here’s how it works: The basic “if” statement from the above example will get replaced by something much harder to understand. Linking it back to the book metaphor, the book will become a very difficult read if you have no clue where the sentence you’re reading belongs within the narrative. Is it from the beginning, middle or end? With control flow obfuscation, it’s impossible to tell.
Arithmetic obfuscation will effectively harden all arithmetic calculations, by replacing them with mathematical equivalents, but much harder to understand computations.
Besides above described obfuscation techniques, code hardening can even be further improved by hiding calls to sensitive API’s, and adding additional encryption layers like string - and class encryption, and in addition to the code level also resource - and asset encryption. The combination of all these techniques will assure that your code is effectively hardened from both offline - and on-device static analysis methods.
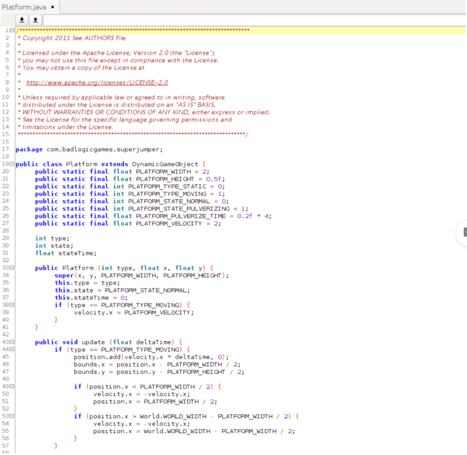
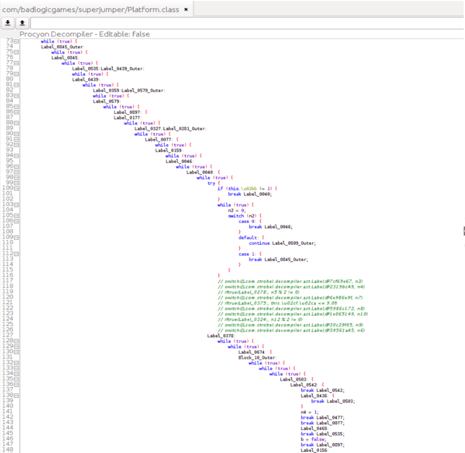
Example 3: The original code snippet (left) vs. properly hardened output (right).
As you’ll notice in the code snippet in Example 3 above, when properly applied, code hardening can effectively protect your app’s source code. This is true not only for humans trying to decipher your code manually, but also for more sophisticated reverse engineering tools like decompilers.
As you can see, name obfuscation impacts readability and intuitiveness of code for humans, but does not impact the understandability of any program logic. It still remains clear what the purpose of any class, function, or calculation is.
This is why, in order to securely harden your code, it is absolutely necessary to layer name obfuscation with additional obfuscation and encryption techniques, like those described in this blog post.
It is the layering of multiple applied code hardening techniques that will make a mobile app too cumbersome to decompile and effectively deter attackers. In addition to these code hardening techniques, it is very effective to include multiple runtime application self-protection (RASP) techniques to secure your app from dynamic attacks. With these techniques fully deployed, app developers can rest assured that their applications will not be low-hanging fruit for hackers.
